
öĄō■ĮYśŗ║═╦ŃĘ©╩ŪŽÓ▌oŽÓ│╔Ą─ĪŻöĄō■ĮYśŗ╩Ū×ķ╦ŃĘ©Ę■䚥─Ż¼╦ŃĘ©ę¬ū„ė├į┌╠žČ©Ą─öĄō■ĮYśŗų«╔ŽĪŻ ę“┤╦Ż¼╬ęéā¤oĘ©╣┬┴óöĄō■ĮYśŗüĒųv╦ŃĘ©Ż¼ę▓¤oĘ©╣┬┴ó╦ŃĘ©üĒųvöĄō■ĮYśŗĪŻ
▒╚╚ńŻ¼ę“×ķöĄĮMŠ▀ėąļSÖCįLå¢Ą─╠ž³cŻ¼│Żė├Ą─Č■Ęų▓ķšę╦ŃĘ©ąĶę¬ė├öĄĮMüĒ┤µā”öĄō■ĪŻĄ½╚ń╣¹╬ęéā▀xō±µ£▒Ē▀@ĘNöĄō■ĮYśŗŻ¼Č■Ęų▓ķšę╦ŃĘ©Š═¤oĘ©╣żū„┴╦Ż¼ę“×ķµ£▒Ē▓ó▓╗ų¦│ųļSÖCįLå¢ĪŻ
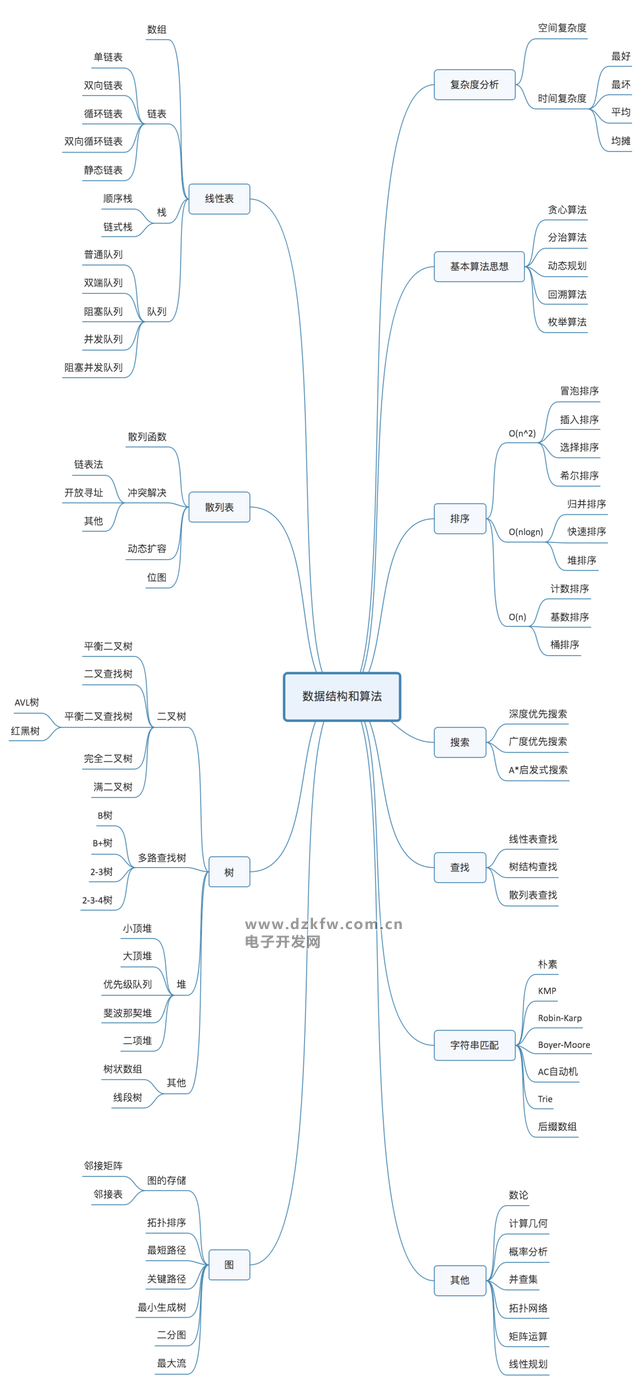
10 éĆöĄō■ĮYśŗŻ║öĄĮMĪóµ£▒ĒĪóŚŻĪóĻĀ┴ąĪó╔ó┴ą▒ĒĪóČ■▓µśõĪóČčĪó╠°▒ĒĪółDĪóTrie śõŻ╗
10 éĆ╦ŃĘ©Ż║▀fÜwĪó┼┼ą“ĪóČ■Ęų▓ķšęĪó╦č╦„Īó╣■ŽŻ╦ŃĘ©ĪóžØą─╦ŃĘ©ĪóĘųų╬╦ŃĘ©Īó╗ž╦▌╦ŃĘ©ĪóäėæBęÄäØĪóūųĘ¹┤«Ųź┼õ╦ŃĘ©ĪŻ
ę¬īW┴Ģ╦³Ą─Ī░üĒÜvĪ▒Ī░ūį╔ĒĄ─╠ž³cĪ▒Ī░▀m║ŽĮŌøQĄ─å¢Ņ}Ī▒ęį╝░Ī░īŹļHĄ─æ¬ė├ł÷Š░Ī▒ĪŻ
Ū¦╚f▓╗ę¬▒╗äėĄžėøæøŻ¼ę¬ČÓ▐qūCĄž╦╝┐╝Ż¼ČÓå¢×ķ╩▓├┤ĪŻ
ę╗ą®┐╔ęįūī─Ń╩┬░ļ╣”▒ČĄ─īW┴Ģ╝╝Ū╔Ż║
-
▀ģīW▀ģŠÜŻ¼▀mČ╚╦óŅ}
-
ČÓå¢ĪóČÓ╦╝┐╝ĪóČÓ╗źäė
-
-
ų¬ūRąĶę¬│┴ĄĒŻ¼▓╗ꬎļįćłDę╗Ž┬ūėšŲ╬š╦∙ėą
īW┴ĢĄ─▀^│╠ųąŻ¼╬ęéā┼÷ĄĮūŅ┤¾Ą─å¢Ņ}Š═╩ŪŻ¼łį│ų▓╗Ž┬üĒĪŻ
╬ęéāį┌┐▌į’Ą─īW┴Ģ▀^│╠ųąŻ¼ę▓┐╔ęįĮoūį╝║įO┴óę╗éĆŪąīŹ┐╔ąąĄ──┐ś╦Ż¼Š═Ž±┤“╣ų╔²╝ēę╗śėĪŻ
1ĪóöĄĮM
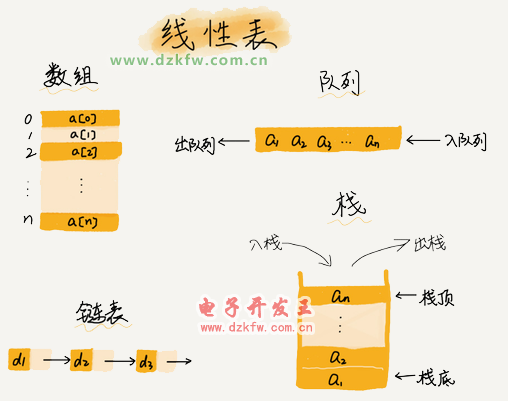
2Īóµ£▒Ē
ŠÅ┤µĄ─┤¾ąĪėąŽ▐Ż¼«öŠÅ┤µ▒╗ė├ØMĢrŻ¼──ą®öĄō■æ¬įō▒╗ŪÕ└Ē│÷╚źŻ¼──ą®öĄō■æ¬įō▒╗▒Ż┴¶Ż┐▀@Š═ąĶꬊÅ┤µ╠į╠Ł▓▀┬įüĒøQČ©ĪŻ│ŻęŖĄ─▓▀┬įėą╚²ĘNŻ║Ž╚▀MŽ╚│÷▓▀┬į FIFOŻ©First InŻ¼First OutŻ®ĪóūŅ╔┘╩╣ė├▓▀┬į LFUŻ©Least Frequently UsedŻ®ĪóūŅĮ³ūŅ╔┘╩╣ė├▓▀┬į LRUŻ©Least Recently UsedŻ®ĪŻ
╚²ĘNūŅ│ŻęŖĄ─µ£▒ĒĮYśŗŻ¼╦³éāĘųäe╩ŪŻ║å╬µ£▒ĒĪóļpŽ“µ£▒Ē║═裣hµ£▒ĒĪŻ
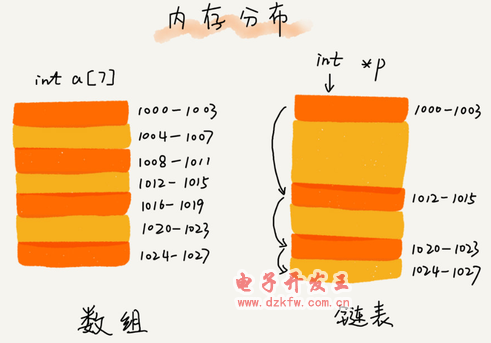
Ż©1Ż®å╬µ£▒Ē
µ£▒Ē═©▀^ųĖßśīóę╗ĮM┴Ń╔óĄ─ā╚┤µēK┤«┬ōį┌ę╗ŲĪŻŲõųąŻ¼╬ęéā░čā╚┤µēKĘQ×ķµ£▒ĒĄ─Ī░ĮY³cĪ▒ĪŻ×ķ┴╦īó╦∙ėąĄ─╣سc┤«ŲüĒŻ¼├┐éƵ£▒ĒĄ─ĮY³c│²┴╦┤µā”öĄō■ų«═ŌŻ¼▀ĆąĶę¬ėøõøµ£╔ŽĄ─Ž┬ę╗éĆ╣سcĄ─ĄžųĘĪŻ╚ńłD╦∙╩ŠŻ¼╬ęéā░č▀@éĆėøõøŽ┬éĆĮY³cĄžųĘĄ─ųĖßśĮąū„║¾└^ųĖßś nextĪŻ
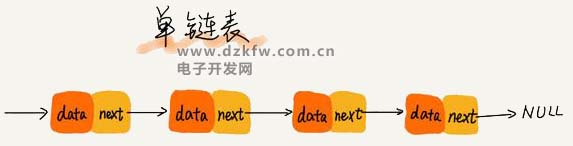
Å─╬ę«ŗĄ─å╬µ£▒ĒłDųąŻ¼─Ńæ¬įō┐╔ęį░l¼FŻ¼Ųõųąėąā╔éĆĮY³c╩Ū▒╚▌^╠ž╩ŌĄ─Ż¼╦³éāĘųäe╩ŪĄ┌ę╗éĆĮY³c║═ūŅ║¾ę╗éĆĮY³cĪŻ╬ęéā┴ĢæTąįĄž░čĄ┌ę╗éĆĮY³cĮąū„Ņ^ĮY³cŻ¼░čūŅ║¾ę╗éĆĮY³cĮąū„╬▓ĮY³cĪŻŲõųąŻ¼Ņ^ĮY³cė├üĒėøõøµ£▒ĒĄ─╗∙ĄžųĘĪŻėą┴╦╦³Ż¼╬ęéāŠ═┐╔ęį▒ķÜvĄ├ĄĮš¹Ślµ£▒ĒĪŻČ°╬▓ĮY³c╠ž╩ŌĄ─ĄžĘĮ╩ŪŻ║ųĖßś▓╗╩ŪųĖŽ“Ž┬ę╗éĆ╣سcŻ¼Č°╩ŪųĖŽ“ę╗éĆ┐šĄžųĘ NULLŻ¼▒Ē╩Š▀@╩Ūµ£▒Ē╔ŽūŅ║¾ę╗éĆ╣سcĪŻ
Ż©2Ż®čŁŁhµ£▒Ē
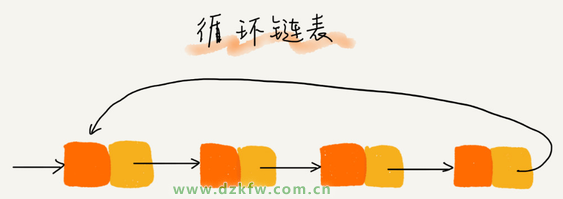
«öę¬╠Ä└ĒĄ─öĄō■Š▀ėąŁhą═ĮYśŗ╠ž³cĢrŻ¼Š═╠žäe▀m║Ž▓╔ė├裣hµ£▒ĒĪŻ▒╚╚ńų°├¹Ą─╝s╔¬Ę“å¢Ņ}ĪŻ
Ż©3Ż®ļpŽ“µ£▒Ē
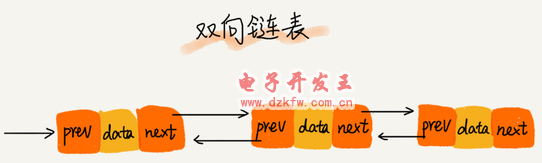
ļpŽ“µ£▒ĒąĶę¬Ņ~═ŌĄ─ā╔éĆ┐šķgüĒ┤µā”║¾└^ĮY³c║═Ū░“īĮY³cĄ─ĄžųĘĪŻ╦∙ęįŻ¼╚ń╣¹┤µā”═¼śėČÓĄ─öĄō■Ż¼ļpŽ“µ£▒Ēę¬▒╚å╬µ£▒Ēš╝ė├Ė³ČÓĄ─ā╚┤µ┐šķgĪŻļm╚╗ā╔éĆųĖßś▒╚▌^└╦┘M┤µā”┐šķgŻ¼Ą½┐╔ęįų¦│ųļpŽ“▒ķÜvŻ¼▀@śėę▓ĦüĒ┴╦ļpŽ“µ£▒Ē▓┘ū„Ą─ņ`╗ŅąįĪŻ
ļpŽ“µ£▒Ē┐╔ęįų¦│ų O(1) ĢrķgÅ═ļsČ╚Ą─ŪķørŽ┬šęĄĮŪ░“īĮY³cĪŻ

╦∙ęįöĄĮM▀m║Žū÷▓ķįāŻ¼▒╚╚ń▓ķįā╦ŃĘ©Č╝╩Ūė├öĄĮMŻ¼µ£▒Ē▀m║Žū÷ā”┤µŻ¼▒╚╚ńlruĢ■┐╝æ]µ£▒ĒĪŻ
╚ń║╬▌p╦╔īæ│÷š²┤_Ą─µ£▒Ē┤·┤aŻ┐
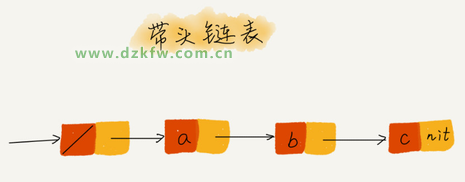
▀ĆėøĄ├╚ń║╬▒Ē╩Šę╗éĆ┐šµ£▒Ēå߯┐head=null ▒Ē╩Šµ£▒Ēųąø]ėąĮY³c┴╦ĪŻŲõųą head ▒Ē╩ŠŅ^ĮY³cųĖßśŻ¼ųĖŽ“µ£▒ĒųąĄ─Ą┌ę╗éĆ╣سcĪŻ
╚ń╣¹╬ęéāę²╚ļ╔┌▒°ĮY³cŻ¼į┌╚╬║╬Ģr║“Ż¼▓╗╣▄µ£▒Ē╩Ū▓╗╩Ū┐šŻ¼head ųĖßśČ╝Ģ■ę╗ų▒ųĖŽ“▀@éĆ╔┌▒°ĮY³cĪŻ╬ęéāę▓░č▀@ĘNėą╔┌▒°ĮY³cĄ─µ£▒ĒĮąÄ¦Ņ^µ£▒ĒĪŻŽÓĘ┤Ż¼ø]ėą╔┌▒°ĮY³cĄ─µ£▒ĒŠ═Įąū„▓╗ĦŅ^µ£▒ĒĪŻ
╔┌▒°ĮY³c╩Ū▓╗┤µā”öĄō■Ą─ĪŻę“×ķ╔┌▒°ĮY³cę╗ų▒┤µį┌Ż¼╦∙ęį▓Õ╚ļĄ┌ę╗éĆĮY³c║═▓Õ╚ļŲõ╦¹ĮY³cŻ¼äh│²ūŅ║¾ę╗éĆ╣سc║═äh│²Ųõ╦¹ĮY³cŻ¼Č╝┐╔ęįĮyę╗×ķŽÓ═¼Ą─┤·┤aīŹ¼F▀ē▌ŗ┴╦ĪŻ
3ĪóŚŻ
«ö─│éĆöĄō■╝»║Žų╗╔µ╝░į┌ę╗Č╦▓Õ╚ļ║═äh│²öĄō■Ż¼▓óŪęØMūŃ║¾▀MŽ╚│÷ĪóŽ╚▀M║¾│÷Ą─╠žąįŻ¼╬ęéāŠ═æ¬įō╩ū▀xĪ░ŚŻĪ▒▀@ĘNöĄō■ĮYśŗĪŻ
▒╚▌^ĮøĄõĄ─ę╗éĆæ¬ė├ł÷Š░Š═╩Ū1Īó ║»öĄš{ė├ŚŻ.2ĪóŚŻį┌▒Ē▀_╩ĮŪ¾ųĄųąĄ─æ¬ė├3ĪóŚŻį┌└©╠¢Ųź┼õųąĄ─æ¬ė├
leetcode╔ŽĻPė┌ŚŻĄ─Ņ}─┐┤¾╝ę┐╔ęįŽ╚ū÷20,155,232,844,224,682,496.
4ĪóĻĀ┴ą
裣hĻĀ┴ą
裣hĻĀ┴ąŻ¼ŅÖ├¹╦╝┴xŻ¼╦³ķLĄ├Ž±ę╗éĆŁhĪŻįŁ▒ŠöĄĮM╩ŪėąŅ^ėą╬▓Ą─Ż¼╩Ūę╗Ślų▒ŠĆĪŻ¼Fį┌╬ęéā░č╩ū╬▓ŽÓ▀BŻ¼░Ō│╔┴╦ę╗éĆŁhĪŻ
ūĶ╚¹ĻĀ┴ą
ūĶ╚¹ĻĀ┴ąŲõīŹŠ═╩Ūį┌ĻĀ┴ą╗∙ĄA╔Žį÷╝ė┴╦ūĶ╚¹▓┘ū„ĪŻ║åå╬üĒšfŻ¼Š═╩Ūį┌ĻĀ┴ą×ķ┐šĄ─Ģr║“Ż¼Å─ĻĀŅ^╚ĪöĄō■Ģ■▒╗ūĶ╚¹ĪŻę“×ķ┤╦Ģr▀Ćø]ėąöĄō■┐╔╚ĪŻ¼ų▒ĄĮĻĀ┴ąųąėą┴╦öĄō■▓┼─▄ĘĄ╗žŻ╗╚ń╣¹ĻĀ┴ąęčĮøØM┴╦Ż¼─Ū├┤▓Õ╚ļöĄō■Ą─▓┘ū„Š═Ģ■▒╗ūĶ╚¹Ż¼ų▒ĄĮĻĀ┴ąųąėą┐šķe╬╗ų├║¾į┘▓Õ╚ļöĄō■Ż¼╚╗║¾į┘ĘĄ╗žĪŻ
▓ó░lĻĀ┴ą
ŠĆ│╠░▓╚½Ą─ĻĀ┴ą╬ęéāĮąū„▓ó░lĻĀ┴ąĪŻūŅ║åå╬ų▒ĮėĄ─īŹ¼FĘĮ╩Į╩Ūų▒Įėį┌ enqueue()Īódequeue() ĘĮĘ©╔Ž╝ėµiŻ¼Ą½╩Ūµi┴ŻČ╚┤¾▓ó░lČ╚Ģ■▒╚▌^Ą═Ż¼═¼ę╗Ģr┐╠āHį╩įSę╗éĆ┤µ╗“š▀╚Ī▓┘ū„ĪŻ
5Īó╠°▒Ē
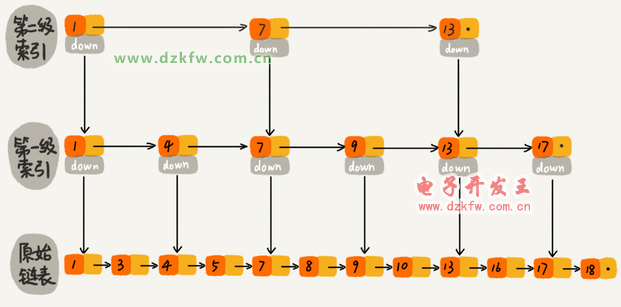
▀@ĘNµ£▒Ē╝ėČÓ╝ē╦„ę²Ą─ĮYśŗŻ¼Š═╩Ū╠°▒ĒĪŻ
ė├╠°▒Ē▓ķįāĄĮĄūėąČÓ┐ņŻ┐
Ą┌ k ╝ē╦„ę²Ą─ĮY³céĆöĄ╩ŪĄ┌ k-1 ╝ē╦„ę²Ą─ĮY³céĆöĄĄ─ 1/2Ż¼─ŪĄ┌ k╝ē╦„ę²ĮY³cĄ─éĆöĄŠ═╩Ū n/(2k)ĪŻ
ĢrķgÅ═ļsČ╚Ż║ O(m*logn)ĪŻ
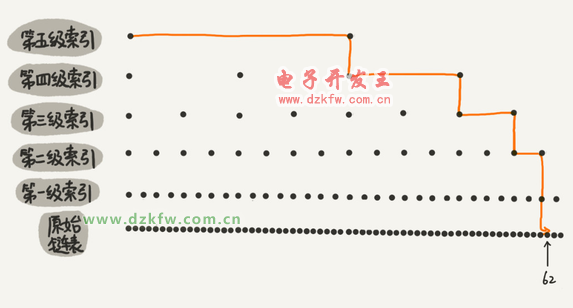
╠°▒Ē╩Ū▓╗╩Ū║▄└╦┘Mā╚┤µŻ┐
╠°▒ĒąĶę¬┤µā”ČÓ╝ē╦„ę²Ż¼┐ŽČ©ę¬Ž¹║─Ė³ČÓĄ─┤µā”┐šķgĪŻ
╠°▒ĒĄ─┐šķgÅ═ļsČ╚╩Ū O(n)ĪŻ
×ķ╩▓├┤ Redis ę¬ė├╠°▒ĒüĒīŹ¼Fėąą“╝»║ŽŻ¼Č°▓╗╩Ū╝t║┌śõŻ┐
Redis ųąĄ─ėąą“╝»║Žų¦│ųĄ─║╦ą─▓┘ū„ų„ę¬ėąŽ┬├µ▀@ÄūéĆŻ║
-
▓Õ╚ļę╗éĆöĄō■Ż╗
-
äh│²ę╗éĆöĄō■Ż╗
-
▓ķšęę╗éĆöĄō■Ż╗
-
░┤ššģ^ķg▓ķšęöĄō■Ż©▒╚╚ń▓ķšęųĄį┌ [100, 356] ų«ķgĄ─öĄō■Ż®Ż╗
-
Ą³┤·▌ö│÷ėąą“ą“┴ąĪŻ
ŲõųąŻ¼▓Õ╚ļĪóäh│²Īó▓ķšęęį╝░Ą³┤·▌ö│÷ėąą“ą“┴ą▀@ÄūéĆ▓┘ū„Ż¼╝t║┌śõę▓┐╔ęį═Ļ│╔Ż¼ĢrķgÅ═ļsČ╚Ė·╠°▒Ē╩Ūę╗śėĄ─ĪŻĄ½╩ŪŻ¼░┤ššģ^ķgüĒ▓ķšęöĄō■▀@éĆ▓┘ū„Ż¼╝t║┌śõĄ─ą¦┬╩ø]ėą╠°▒ĒĖ▀ĪŻ
ī”ė┌░┤ššģ^ķg▓ķšęöĄō■▀@éĆ▓┘ū„Ż¼╠°▒Ē┐╔ęįū÷ĄĮ O(logn) Ą─ĢrķgÅ═ļsČ╚Č©╬╗ģ^ķgĄ─Ų³cŻ¼╚╗║¾į┌įŁ╩╝µ£▒ĒųąĒśą“═∙║¾▒ķÜvŠ═┐╔ęį┴╦ĪŻ▀@śėū÷ĘŪ│ŻĖ▀ą¦ĪŻ
▀ĆėąŻ¼╠°▒ĒĖ³╝ėņ`╗ŅŻ¼╦³┐╔ęį═©▀^Ė─ūā╦„ę²śŗĮ©▓▀┬įŻ¼ėąą¦ŲĮ║Ōł╠ąąą¦┬╩║═ā╚┤µŽ¹║─ĪŻ
6ĪóČ■▓µśõ
7ĪóTrieśõŻ©ūųĄõśõŻ®
Trie śõŻ¼ę▓ĮąĪ░ūųĄõśõĪ▒ĪŻŅÖ├¹╦╝┴xŻ¼╦³╩Ūę╗éĆśõą╬ĮYśŗĪŻ╦³╩Ūę╗ĘNīŻķT╠Ä└ĒūųĘ¹┤«Ųź┼õĄ─öĄō■ĮYśŗŻ¼ė├üĒĮŌøQį┌ę╗ĮMūųĘ¹┤«╝»║Žųą┐ņ╦┘▓ķšę─│éĆūųĘ¹┤«Ą─å¢Ņ}ĪŻ
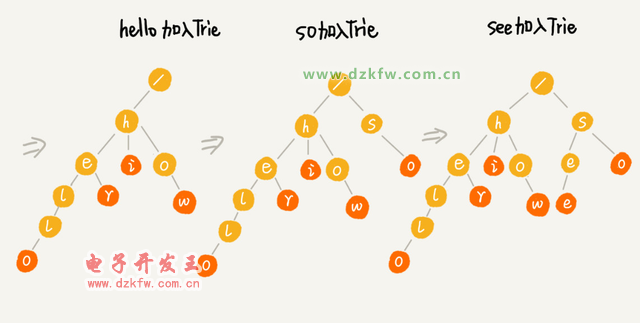
Trie śõų„ę¬ėąā╔éĆ▓┘ū„
-
ę╗éĆ╩ŪīóūųĘ¹┤«╝»║Žśŗįņ│╔ Trie śõŻ¼Š═╩Ūę╗éĆīóūųĘ¹┤«▓Õ╚ļĄĮ Trie śõĄ─▀^│╠ĪŻ
-
┴Ēę╗éĆ╩Ūį┌ Trie śõųą▓ķįāę╗éĆūųĘ¹┤«ĪŻ
Trie śõĄ─ūā¾wėą║▄ČÓŻ¼Č╝┐╔ęįį┌ę╗Č©│╠Č╚╔ŽĮŌøQā╚┤µŽ¹║─Ą─å¢Ņ}ĪŻ▒╚╚ńŻ¼┐s³cā×╗»
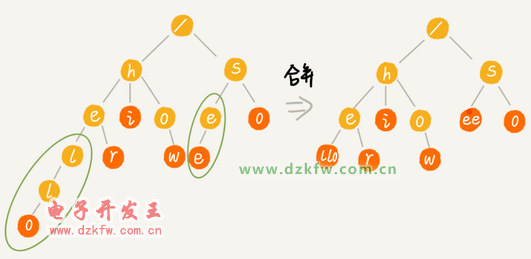
į┌ę╗ĮMūųĘ¹┤«ųą▓ķšęūųĘ¹┤«Ż¼Trie śõīŹļH╔Ž▒Ē¼FĄ├▓ó▓╗║├ĪŻ╦³ī”ę¬╠Ä└ĒĄ─ūųĘ¹┤«ėą╝░Ųõć└┐┴Ą─ę¬Ū¾ĪŻ
-
Ą┌ę╗Ż¼ūųĘ¹┤«ųą░³║¼Ą─ūųĘ¹╝»▓╗─▄╠½┤¾ĪŻ╬ęéāŪ░├µųvĄĮŻ¼╚ń╣¹ūųĘ¹╝»╠½┤¾Ż¼─Ū┤µā”┐šķg┐╔─▄Š═Ģ■└╦┘M║▄ČÓĪŻ╝┤▒Ń┐╔ęįā×╗»Ż¼Ą½ę▓ę¬ĖČ│÷Ā▐╔³▓ķįāĪó▓Õ╚ļą¦┬╩Ą─┤·ārĪŻ
-
Ą┌Č■Ż¼ę¬Ū¾ūųĘ¹┤«Ą─Ū░ŠYųž║Ž▒╚▌^ČÓŻ¼▓╗╚╗┐šķgŽ¹║─Ģ■ūā┤¾║▄ČÓĪŻ
-
Ą┌╚²Ż¼╚ń╣¹ę¬ė├ Trie śõĮŌøQå¢Ņ}Ż¼─Ū╬ęéāŠ═ę¬ūį╝║Å─┴Ńķ_╩╝īŹ¼Fę╗éĆ Trie śõŻ¼▀Ćę¬▒ŻūCø]ėą bugŻ¼▀@éĆį┌╣ż│╠╔Ž╩Ūīó║åå╬å¢Ņ}Å═ļs╗»Ż¼│²ĘŪ▒žĒÜŻ¼ę╗░Ń▓╗Į©ūh▀@śėū÷ĪŻ
-
Ą┌╦─Ż¼╬ęéāų¬Ą└Ż¼═©▀^ųĖßś┤«ŲüĒĄ─öĄō■ēK╩Ū▓╗▀B└mĄ─Ż¼Č° Trie śõųąė├ĄĮ┴╦ųĖßśŻ¼╦∙ęįŻ¼ī”ŠÅ┤µ▓ó▓╗ėč║├Ż¼ąį─▄╔ŽĢ■┤“éĆš█┐█ĪŻ
ŠC║Ž▀@Äū³cŻ¼ßśī”į┌ę╗ĮMūųĘ¹┤«ųą▓ķšęūųĘ¹┤«Ą─å¢Ņ}Ż¼╬ęéāį┌╣ż│╠ųąŻ¼Ė³āAŽ“ė┌ė├╔ó┴ą▒Ē╗“š▀╝t║┌śõĪŻę“×ķ▀@ā╔ĘNöĄō■ĮYśŗŻ¼╬ęéāČ╝▓╗ąĶę¬ūį╝║╚źīŹ¼FŻ¼ų▒Įė└¹ė├ŠÄ│╠šZčįųą╠ß╣®Ą─¼F│╔ŅÉÄņŠ═ąą┴╦ĪŻ
īŹļH╔ŽŻ¼Trie śõų╗╩Ū▓╗▀m║ŽŠ½┤_Ųź┼õ▓ķšęŻ¼▀@ĘNå¢Ņ}Ė³▀m║Žė├╔ó┴ą▒Ē╗“š▀╝t║┌śõüĒĮŌøQĪŻTrie śõ▒╚▌^▀m║ŽĄ─╩Ū▓ķšęŪ░ŠYŲź┼õĄ─ūųĘ¹┤«Ż¼ę▓Š═╩ŪŅÉ╦Ųķ_Ų¬å¢Ņ}Ą──ŪĘNł÷Š░ĪŻ
8Īó╔ó┴ą▒ĒŻ©Hash TableŻ®
╔ó┴ą▒ĒŻ©╣■ŽŻ▒ĒŻ®ė├Ą─╩ŪöĄĮMų¦│ų░┤ššŽ┬ś╦ļSÖCįLå¢öĄō■Ą─╠žąįŻ¼╦∙ęį╔ó┴ą▒ĒŲõīŹŠ═╩ŪöĄĮMĄ─ę╗ĘNöUš╣Ż¼ė╔öĄĮMč▌╗»Č°üĒĪŻ┐╔ęįšfŻ¼╚ń╣¹ø]ėąöĄĮMŻ¼Š═ø]ėą╔ó┴ą▒ĒĪŻ
ę╗░Ńėąkey║═valueŻ¼keyĢ■═©▀^╔ó┴ą║»öĄ▐DōQ│╔╔ó┴ąųĄ
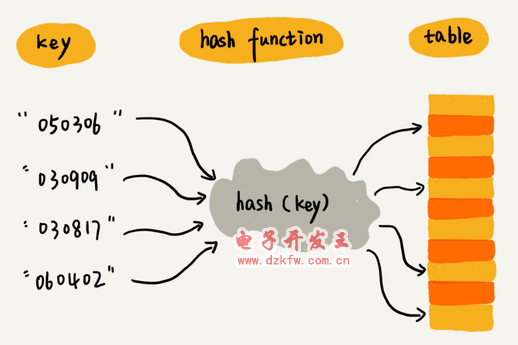
╔ó┴ą║»öĄŻ©╣■ŽŻ║»öĄŻ®
╔ó┴ą▒Ēā╔éĆ║╦ą─å¢Ņ}╩Ū╔ó┴ą║»öĄįOėŗ║═╔ó┴ąø_═╗ĮŌøQĪŻ
╔ó┴ą║»öĄįOėŗĄ─╗∙▒Šę¬Ū¾Ż║
-
╔ó┴ą║»öĄėŗ╦ŃĄ├ĄĮĄ─╔ó┴ąųĄ╩Ūę╗éĆĘŪžōš¹öĄŻ╗
-
╚ń╣¹ key1 = key2Ż¼─Ū hash(key1) == hash(key2)Ż╗
-
╚ń╣¹ key1 Ī┘ key2Ż¼─Ū hash(key1) Ī┘ hash(key2)ĪŻ
Ą┌ę╗Č■³cø]╔Čå¢Ņ}Ż¼Ą½Ą┌╚²³c└ĒĮŌŲüĒ┐╔─▄Ģ■ėąå¢Ņ}Ż¼ę¬ŽļšęĄĮę╗éĆ▓╗═¼Ą─ key ī”æ¬Ą─╔ó┴ąųĄČ╝▓╗ę╗śėĄ─╔ó┴ą║»öĄŻ¼Äū║§╩Ū▓╗┐╔─▄Ą─ĪŻ╝┤▒ŃŽ±śIĮńų°├¹Ą─MD5ĪóSHAĪóCRCĄ╚╣■ŽŻ╦ŃĘ©Ż¼ę▓¤oĘ©═Ļ╚½▒▄├Ō▀@ĘN╔ó┴ąø_═╗ĪŻČ°ŪęŻ¼ę“×ķöĄĮMĄ─┤µā”┐šķgėąŽ▐Ż¼ę▓Ģ■╝ė┤¾╔ó┴ąø_═╗Ą─Ė┼┬╩ĪŻ
╬ęéā│Żė├Ą─╔ó┴ąø_═╗ĮŌøQĘĮĘ©ėąā╔ŅÉŻ¼ķ_Ę┼īżųĘĘ©║═µ£▒ĒĘ©ĪŻ
1. ķ_Ę┼īżųĘĘ©
ķ_Ę┼īżųĘĘ©Ą─║╦ą─╦╝Žļ╩ŪŻ¼╚ń╣¹│÷¼F┴╦╔ó┴ąø_═╗Ż¼╬ęéāŠ═ųžą┬╠Į£yę╗éĆ┐šķe╬╗ų├Ż¼īóŲõ▓Õ╚ļĪŻ
-
ŠĆąį╠Į£yŻ║╚ń╣¹┤µā”╬╗ų├ęčĮø▒╗š╝ė├┴╦Ż¼╬ęéāŠ═Å─«öŪ░╬╗ų├ķ_╩╝Ż¼ę└┤╬═∙║¾▓ķšęŻ¼┐┤╩Ūʱėą┐šķe╬╗ų├Ż¼ų▒ĄĮšęĄĮ×ķų╣ĪŻ
-
Č■┤╬╠Į£yŻ║Ė·ŠĆąį╠Į£y║▄Ž±Ż¼ŠĆąį╠Į£y├┐┤╬╠Į£yĄ─▓ĮķL╩Ū 1Ż¼─Ū╦³╠Į£yĄ─Ž┬ś╦ą“┴ąŠ═╩Ū hash(key)+0Ż¼hash(key)+1Ż¼hash(key)+2ĪŁĪŁČ°Č■┤╬╠Į£y╠Į£yĄ─▓ĮķLŠ═ūā│╔┴╦įŁüĒĄ─Ī░Č■┤╬ĘĮĪ▒Ż¼ę▓Š═╩ŪšfŻ¼╦³╠Į£yĄ─Ž┬ś╦ą“┴ąŠ═╩Ū hash(key)+0Ż¼hash(key)+12Ż¼hash(key)+22ĪŁĪŁ
-
ļpųž╔ó┴ąŻ║ęŌ╦╝Š═╩Ū▓╗āHę¬╩╣ė├ę╗éĆ╔ó┴ą║»öĄĪŻ╬ęéā╩╣ė├ę╗ĮM╔ó┴ą║»öĄ hash1(key)Ż¼hash2(key)Ż¼hash3(key)ĪŁĪŁ╬ęéāŽ╚ė├Ą┌ę╗éĆ╔ó┴ą║»öĄŻ¼╚ń╣¹ėŗ╦ŃĄ├ĄĮĄ─┤µā”╬╗ų├ęčĮø▒╗š╝ė├Ż¼į┘ė├Ą┌Č■éĆ╔ó┴ą║»öĄŻ¼ę└┤╬ŅÉ═ŲŻ¼ų▒ĄĮšęĄĮ┐šķeĄ─┤µā”╬╗ų├ĪŻ
«ööĄō■┴┐▒╚▌^ąĪĪóčb▌dę“ūėąĪĄ─Ģr║“Ż¼▀m║Ž▓╔ė├ķ_Ę┼īżųĘĘ©ĪŻ▀@ę▓╩Ū Java ųąĄ─ThreadLocalMap╩╣ė├ķ_Ę┼īżųĘĘ©ĮŌøQ╔ó┴ąø_═╗Ą─įŁę“ĪŻ
2. µ£▒ĒĘ©
╦∙ėą╔ó┴ąųĄŽÓ═¼Ą─į¬╦ž╬ęéāČ╝Ę┼ĄĮŽÓ═¼▓█╬╗ī”æ¬Ą─µ£▒ĒųąĪŻ
×ķ╩▓├┤HashMap╩╣ė├µ£▒ĒĘ©ĮŌøQ╣■ŽŻø_═╗
1Īó╩ūŽ╚Ż¼µ£▒ĒĘ©ī”ā╚┤µĄ─└¹ė├┬╩▒╚ķ_Ę┼īżųĘĘ©ę¬Ė▀ĪŻę“×ķµ£▒ĒĮY³c┐╔ęįį┌ąĶꬥ─Ģr║“į┘äōĮ©Ż¼▓ó▓╗ąĶꬎ±ķ_Ę┼īżųĘĘ©─Ūśė╩┬Ž╚╔Ļšł║├ĪŻīŹļH╔ŽŻ¼▀@ę╗³cę▓╩Ū╬ęéāŪ░├µųv▀^Ą─µ£▒Ēā×ė┌öĄĮMĄ─ĄžĘĮĪŻ
2Īóµ£▒ĒĘ©▒╚Ųķ_Ę┼īżųĘĘ©Ż¼ī”┤¾čb▌dę“ūėĄ─╚▌╚╠Č╚Ė³Ė▀ĪŻķ_Ę┼īżųĘĘ©ų╗─▄▀mė├čb▌dę“ūėąĪė┌ 1 Ą─ŪķørĪŻĮėĮ³ 1 ĢrŻ¼Š═┐╔─▄Ģ■ėą┤¾┴┐Ą─╔ó┴ąø_═╗Ż¼ī¦ų┬┤¾┴┐Ą─╠Į£yĪóį┘╔ó┴ąĄ╚Ż¼ąį─▄Ģ■Ž┬ĮĄ║▄ČÓĪŻĄ½╩Ūī”ė┌µ£▒ĒĘ©üĒšfŻ¼ų╗ę¬╔ó┴ą║»öĄĄ─ųĄļSÖCŠ∙ä“Ż¼╝┤▒Ńčb▌dę“ūėūā│╔ 10Ż¼ę▓Š═╩Ūµ£▒ĒĄ─ķLČ╚ūāķL┴╦Č°ęčŻ¼ļm╚╗▓ķšęą¦┬╩ėą╦∙Ž┬ĮĄŻ¼Ą½╩Ū▒╚ŲĒśą“▓ķšę▀Ć╩Ū┐ņ║▄ČÓĪŻ
 ĘĄ╗žĒö▓┐
ĘĄ╗žĒö▓┐ ╦óą┬Ēō├µ
╦óą┬Ēō├µ Ž┬ĄĮĒōĄū
Ž┬ĄĮĒōĄū